CUDA 是一套運用 GPU 大量核心的程式語法和介面,讓程式碼由 GPU 的多執行緒來執行,藉此來達到比 CPU 更加快速的執行效能。實際應用可參考這篇文章: Accelerating Brain Mask Generation with CUDA in Python,這篇文章介紹了如何使用 CUDA 來加速腦部遮罩生成的過程。
Kernel 就相當於我們所學的函式(Function),只是這個函式是由 GPU 來執行的,因此在定義這個函式時,需要用 CUDA 的巨集來修飾函式,讓編譯器知道這段函式內容是由 GPU 來執行,而通常 Kernel 處理的對象會是 Vector、Array 或 Matrix。
我們來看看 C/C++ 和 Python 範例:
__global__ void vector_addition(float* a, float* b, float* c)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
...
vector_addition<<<1, N>>>(a, b, c) // Kernel invocation with N threads
...
}
@jit(nopython=True)
def vector_addition(a, b, c):
int i = threadIdx.x;
c[i] = a[i] + b[i];
vector_addition(a, b, c)
執行緒可以是一維、二維或三維,這些都統稱為 thread block,而一個 thread block 預期會常駐於在相同匯流的多處理器核心之中,且它們必須共享限制的記憶體資源,在當今的GPU中,一個 thread block 可擁有1024條執行緒,總執行緒數量為 thread block 含有的執行緒 * thread block 數量。
多個 thread block 可構成一個 grid,block 的數量通常由處理的資料大小來做決定,通常數量會大於系統中的處理器數量。
執行緒群會存取多個記憶體空間,每個執行緒擁有自己私有的區域記憶體。每個 thread block 都有共享記憶體,所有在 block 內的執行緒都可使用,且共享記憶體的生命週期與 block 相同。所有執行緒都可存取相同的全域記憶體。
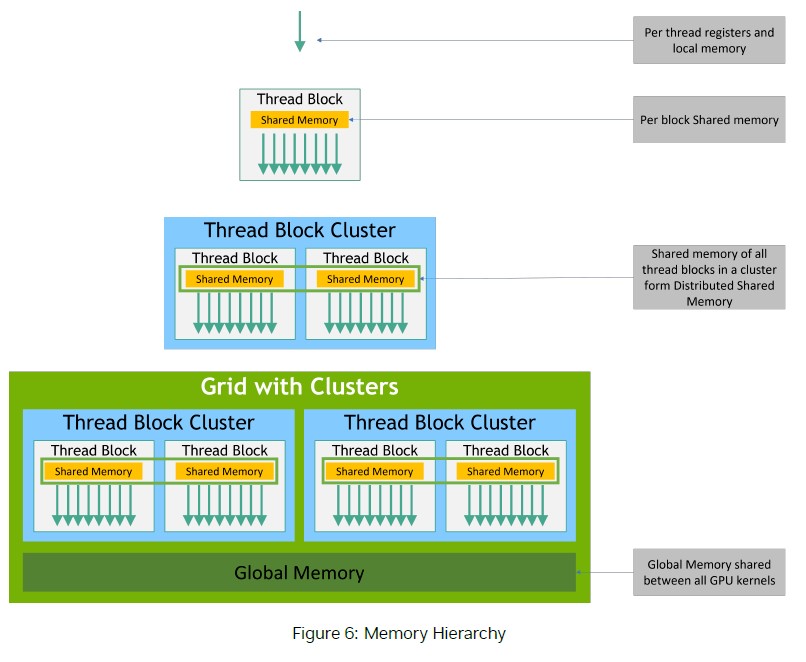 (圖片來源: CUDA C++ Programming Guide pdf)
(圖片來源: CUDA C++ Programming Guide pdf)
Python 要實現 CUDA 可依據不同 Package 有不同的實現方式,這裡我就以 numba 這個 package 為例,用 CUDA 將圖片背景透明化。
import numpy as np
from PIL import Image
from numba import jit, cuda
def CUDA_Init(img_np):
self.threads_per_block = (16, 16)
self.blocks_per_grid_x = (img_np.shape[0] + self.threads_per_block[0] - 1) // self.threads_per_block[0]
self.blocks_per_grid_y = (img_np.shape[1] + self.threads_per_block[1] - 1) // self.threads_per_block[1]
@cuda.jit
def perspective_background(img_np):
width, height = img_np.shape[0], img_np.shape[1]
x, y = cuda.grid(2)
for x in range(0, width):
for y in range(0, height):
r, g, b = img_np[x][y][0], img_np[x][y][1], img_np[x][y][2]
if r <= 10 and g <= 10 and b <= 10:
img_np[x][y][3] = 0
img = Image.open("image.jpg")
img_np = np.array(img.convert("RGBA"), dtype=np.uint8)
CUDA_Init(img_np)
d_img = cuda.to_device(img_np) # 將圖像的 numpy array 載入到 GPU device
perspective_background[(self.blocks_per_grid_x, self.blocks_per_grid_y), self.threads_per_block](d_img)
result_img_np = d_img.copy_to_host() # 將處理完成的圖片讀取回來
Last updated: