Once we’ve generated the brain mask maps using our CUDA-based mask generator (article), the next step is to train an AI model to learn how to extract brain tissue regions directly from DICOM medical images.
I’ll skip the image loading, dataset construction, and basic preprocessing steps here and focus on the model architecture and training strategy, which are the more relevant parts for this article.
Here’s the complete code on GitHub for reference.
For the segmentation task, I used a very simple convolutional neural network (CNN) with an encoder-decoder architecture — a structure that’s quite common in image segmentation problems.
The encoder consists of several convolution + max pooling layers to downsample the input, while the decoder uses transposed convolution layers to upsample the feature maps back to the original size. Here’s the model constructor (__init__):
import torch.nn as nn
class SimpleSegNet(nn.Module):
def __init__(self):
super(SimpleSegNet, self).__init__()
# Encoder
self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)
self.pool1 = nn.MaxPool2d(2, 2) # 256 -> 128
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, padding=1)
self.pool2 = nn.MaxPool2d(2, 2) # 128 -> 64
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool3 = nn.MaxPool2d(2, 2) # 64 -> 32
# Decoder
self.up1 = nn.ConvTranspose2d(64, 32, kernel_size=2, stride=2)
self.up2 = nn.ConvTranspose2d(32, 16, kernel_size=2, stride=2)
self.up3 = nn.ConvTranspose2d(16, 1, kernel_size=2, stride=2)
During the forward pass, we apply ReLU activations after each convolutional or transposed convolutional layer except for the final layer, where we skip ReLU to preserve raw logits — necessary for BCEWithLogitsLoss.
def forward(self, x):
x = torch.relu(self.conv1(x)) # (B, 16, 256, 256)
x = self.pool1(x) # (B, 16, 128, 128)
x = torch.relu(self.conv2(x)) # (B, 32, 128, 128)
x = self.pool2(x) # (B, 32, 64, 64)
x = torch.relu(self.conv3(x)) # (B, 64, 64, 64)
x = self.pool3(x) # (B, 64, 32, 32)
x = torch.relu(self.up1(x)) # (B, 32, 64, 64)
x = torch.relu(self.up2(x)) # (B, 16, 128, 128)
x = self.up3(x) # (B, 1, 256, 256) → final logits
return x
Since we’re using BCEWithLogitsLoss, we don’t apply a sigmoid() on the output logits before computing loss — the loss function handles that internally.
import torch
from tqdm import tqdm
epochs = 30
torch.manual_seed(42)
torch.cuda.manual_seed_all(42)
for epoch in tqdm(range(epochs)):
model.train()
running_loss = 0.0
accuracy = 0.0
for i in range(len(training_images_tensor)):
inputs = training_images_tensor[i].unsqueeze(0).unsqueeze(0).float()
labels = training_labels_tensor[i].unsqueeze(0).unsqueeze(0).float()
outputs = model(inputs)
loss = loss_function(outputs, labels)
mask_map = sigmoid_to_mask(outputs)
accuracy += accuracy_fn(mask_map.view(-1), labels.view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f"Epoch [{epoch+1}/{epochs}], Loss: {running_loss/len(training_images_tensor):.4f}, Accuracy: {accuracy/len(training_images_tensor):.2f}%")
Note: Based on experiments, training beyond 10 epochs didn’t yield noticeable improvements — the loss and accuracy curves plateaued quickly.
Here’s what the training curve looks like (loss vs. accuracy):
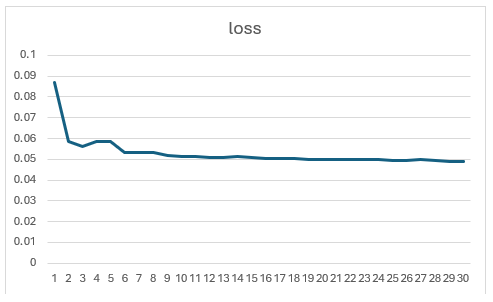
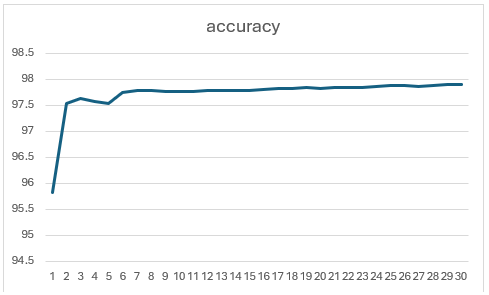
Visually, the predicted brain masks are mostly accurate, though some edges appear fragmented or rough. There’s room for improvement in the boundary continuity.
In future iterations, I plan to experiment with deeper encoder-decoder structures, or perhaps introduce skip connections (like in U-Net), to see if that improves the mask quality, especially at tissue boundaries.
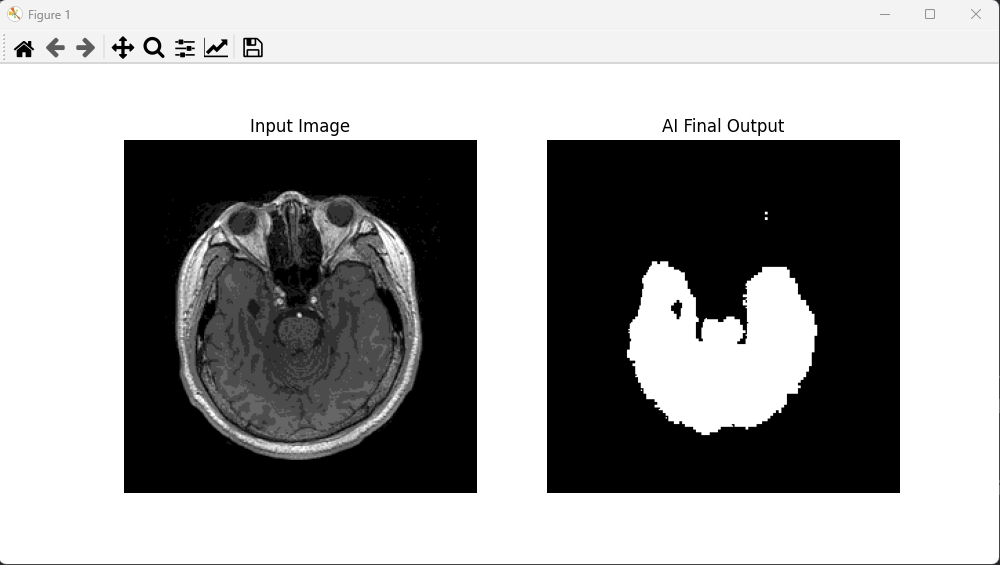
Last updated: