CUDA (Compute Unified Device Architecture) is a parallel computing platform and application programming interface (API) model created by NVIDIA. It allows developers to use NVIDIA GPUs for general purpose processing (an approach known as GPGPU, General-Purpose computing on Graphics Processing Units).
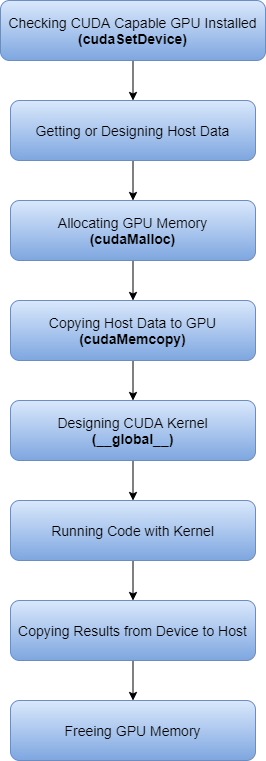
This article records some key learning points about designing a simple CUDA kernel, along with the basic workflow and core concepts.
When it comes to kernels, there are a few important points to note:
A kernel function is declared with the __global__ specifier. Aside from this, its definition is similar to a regular function.
A kernel represents the work executed in parallel by each GPU thread. Inside a kernel, you can access built-in variables such as threadIdx to identify the current thread.
Thread Hierarchy
Threads can be organized in one, two, or three dimensions. These groups of threads are called thread blocks, and can be declared using the dim3 or int keyword.
A thread block is expected to reside on the same streaming multiprocessor (SM), where its threads share limited memory resources. On modern GPUs, a single block can contain up to 1024 threads. The total number of threads is given by:
Total threads = Threads per block × Number of blocks
To cover the entire dataset, the total number of threads must be computed as block × grid, ensuring that all elements are processed.
Multiple thread blocks form a grid. The number of blocks is usually determined by the dataset size and is often larger than the number of available multiprocessors.
The thread ID within a grid can be calculated using the formula:
threadID = threadIdx + blockIdx * blockDim
Here, blockDim refers to the length of a block in a given dimension. For example, blockDim.x represents the block length along the X-axis.